ETL, ELT, pipelining, Data engineering, what do these terms mean, why does it matter, how are they different? If these are questions that you have, then you are already on the road to becoming a data professional.
Simply put, a data pipeline is a tool/mechanism that enables the flow of data from point A to point B with a few intermediate steps. Some of these steps include other commonly used terms that you may have encountered such as Data cleaning, Data processing, Data governance and the like.
Using the aforementioned analogy, point A would be considered a “Data Source”, point B would be the “Data Consumer” and the intermediary would be the “pipeline” so to speak”.
Why are they important?
This begs the question, why do we need this “pipeline” at all.
Well, given the plethora of data sources that most companies will be working with, in conjunction with the numerous machine learning, AI, or even simple reporting tasks that rely on said data, it is incredibly paramount that the data itself is of the highest quality.
This is done using the steps mentioned above.
Difference between ETL & Data Pipeline
All of this being said, what is the difference between ETL and a data pipeline? ETL stands for extract, transform and load, and is typically used by most organizations for scheduled batch processing of large volumes of data. However, ETL is but one of the types of processing methods that could be considered a data pipeline, in other words, Data Pipeline is an all encompassing term.
There are many instances where processing of real-time data is required in which case, scheduled batch processing or ETL would not be ideal. Here, a data pipeline that performs real-time processing would be preferred.
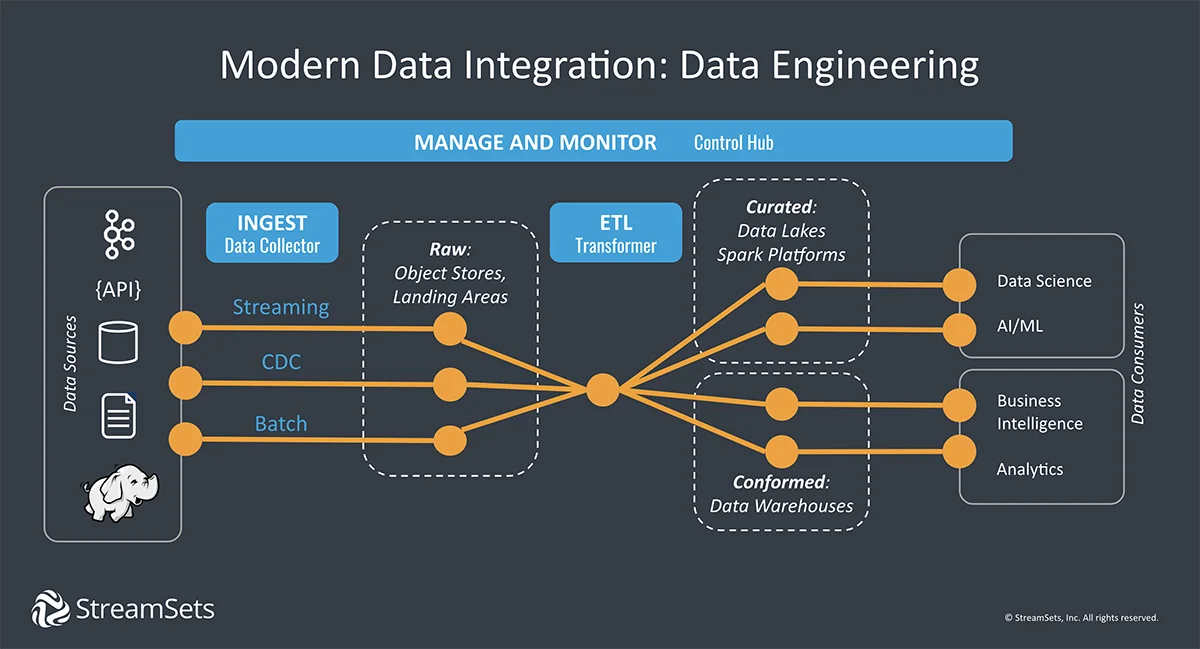
Architecture of a Data Pipeline
Lets take a look at the architecture of a data pipeline. There are two types of data sources, one which would require batch processing, such as databases and mainframes, and another which requires real time processing such as IOT sensors, speedometers etc. For the former, an ETL tool such as SAP BODS would be the perfect solution and for the latter, a tool such as Apache Kafka would be ideal for message stream ingestion.
Once the data has been processed, it may be stored either in a data lake or a data warehouse such as Google Bigquery or Teradata respectively for use by a BI tool such as Tableau or PowerBI or in other machine learning/AI applications.
Summary
In summary, data pipelines are the cornerstone of data analytics and data science applications because they ensure that the structured or unstructured data that it is fed, is processed appropriately.



